Advancements in Open Source Programming with ByteIR
Introduction to ByteIR: An End-to-end Model Compilation Solution
At its core, ByteIR aims to revolutionize the way machine-learning programs are created and deployed. Its architecture is meticulously designed to simplify these processes, making it more accessible for developers to bring their machine learning models to life. This commitment to ease-of-use without sacrificing performance is one of the key aspects that differentiates ByteIR from other tools in the market.
One of the most compelling features of ByteIR is its end-to-end model compilation capability. This feature streamlines the transition from model development to runtime deployment, ensuring a seamless workflow. By integrating various stages of model compilation, ByteIR significantly reduces the complexity and time required to bring a machine learning model into production. At its core, ByteIR delivers a suite of optimization passes designed for exceptional performance while maintaining a unified intermediate representation that is compatible with a wide array of devices.
Furthermore, ByteIR’s open-source nature fosters a collaborative environment, encouraging contributions from a wide range of developers and researchers. This community-driven approach ensures continuous improvement and innovation, making ByteIR not just a tool but a constantly evolving ecosystem that adapts to the ever-changing demands of machine learning development.
ByteIR is not just a tool but a groundbreaking solution in the realm of machine learning. Its emphasis on simplifying the creation and deployment of machine-learning programs, combined with its unique end-to-end model compilation feature, sets it apart in the open-source programming landscape. With ByteDance’s backing, ByteIR is poised to become an indispensable asset for developers and researchers in the field of machine learning.
The ByteIR Framework: A Dive into Its Mechanics
The ByteIR Framework stands as an excellent example of compiler architecture, particularly in the realm of machine learning. Its mechanics are rooted in three key components: the Frontends, Compiler, and Runtime. Each of these elements plays a vital role in the framework’s overall functionality, contributing to its efficiency and effectiveness.
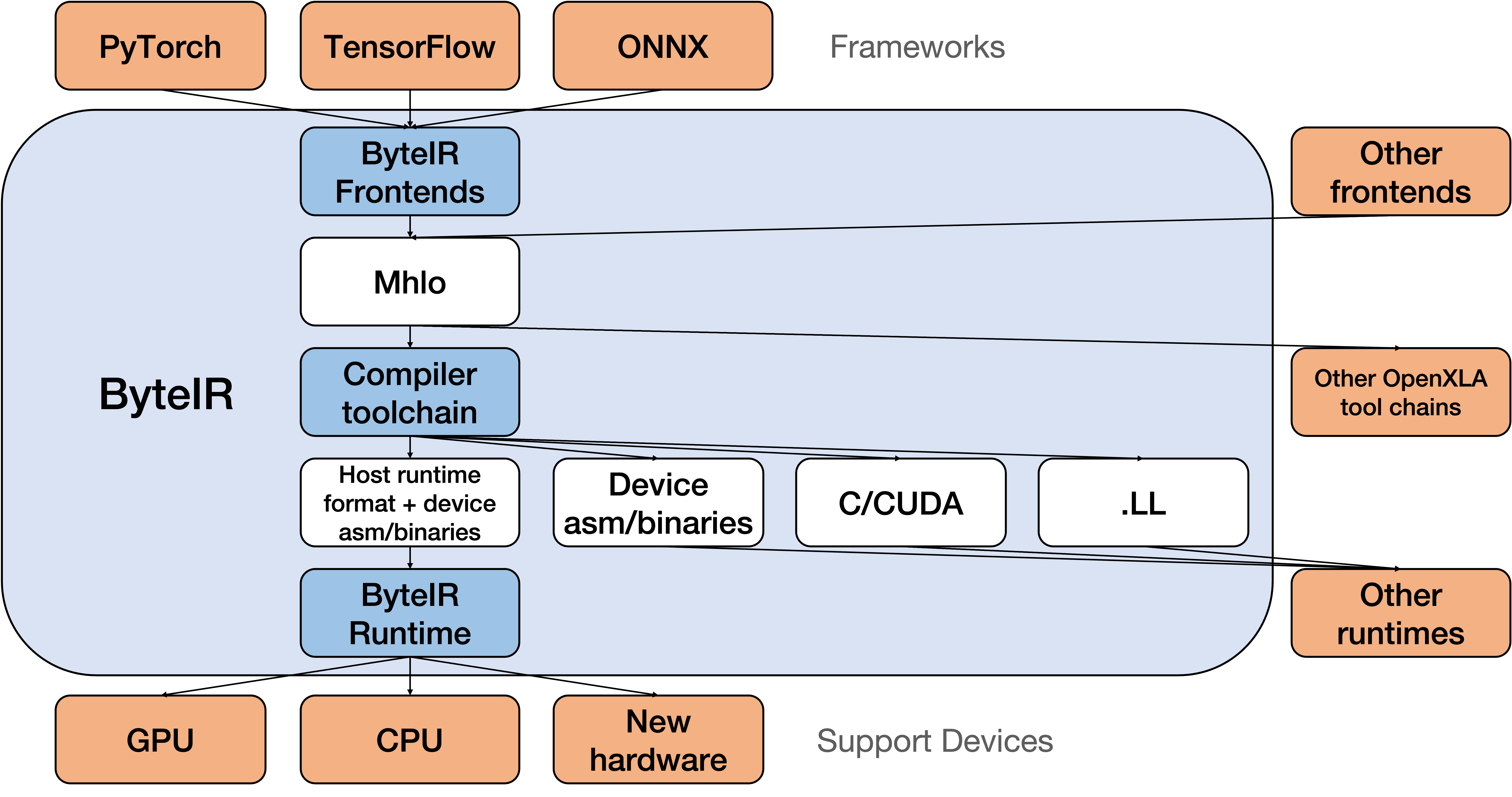
Firstly, Frontends in ByteIR serve as the interface for developers, allowing them to interact with the framework using familiar programming languages and tools. They translate models written in PyTorch, TensorFlow, or ONNX, into Mhlo dialect, which is the intermediate representation that ByteIR’s Compiler can understand and optimize. This translation is a critical step in making ByteIR accessible to a wide range of developers, irrespective of their preferred programming language, and provides a unified type of input for the compiler.
The Compiler in ByteIR is a sophisticated engine that processes and optimizes machine learning models. It employs optimization passes to transform high-level code into an optimized form, making it more efficient for execution. This optimization is crucial for performance-critical applications, ensuring that models run swiftly and effectively. For example, we provide CAT dialect to lower into AITemplate backend for Nvidia GPU. What’s more, we provide a series of Linalg Extensions. We not only implement more ops for the original Linalg dialect, but also provide enhanced transformations that are useful for fusion, tiling, etc.
The Runtime component of ByteIR is equally essential. It acts as the execution environment for the optimized models, managing resources and handling interactions with the underlying hardware. This includes memory allocation management, a collection of operation runtime implementations, and a work queue for execution. The Runtime ensures that the optimized code produced by the Compiler is executed seamlessly, providing a robust platform for running complex machine learning models.
In essence, the ByteIR Framework’s mechanics are a symphony of well-orchestrated components, each contributing its unique functionality. The Compiler’s optimization capabilities, coupled with the Runtime’s efficient execution environment and the Frontends’ user-friendly interfaces, make ByteIR a powerful tool in the realm of machine learning model compilation. The framework’s use of MLIR dialects and ByRE interfaces exemplifies its innovative approach to facilitating smooth and efficient communication across its various components.
ByteIR and Compatibility: Meeting MLIR Dialects
The seamless interaction between these components is a cornerstone of ByteIR’s design. Communication within the framework is facilitated through MLIR dialects including Mhlo, Linalg, ByRE, CAT, etc. MLIR dialects provide a flexible way to represent different levels of abstraction in the code, allowing the Compiler to understand and optimize various parts of the model effectively. We also have several interface dialects, on the other hand, to ensure seamless communication between the Compiler and Runtime, enabling efficient execution of optimized models. MLIR (Multi-Level Intermediate Representation) dialects play a crucial role in enhancing the compatibility of the ByteIR Framework across various levels of abstraction and computational paradigms. This is achieved through several key mechanisms:
Layered Abstraction: MLIR dialects enable ByteIR to operate at multiple levels of abstraction. This means that the framework can efficiently handle everything from high-level algorithmic descriptions to low-level hardware-specific optimizations. By providing these multiple layers, MLIR dialects ensure that ByteIR remains compatible with a wide range of machine learning models and hardware architectures.
Modular Design: The dialects in MLIR are inherently modular. This modularity allows ByteIR to integrate new functionalities or support for new hardware without overhauling the entire system. As new computational technologies emerge, ByteIR can adapt by simply adding new dialects, ensuring ongoing compatibility with the evolving landscape of machine learning and computing.
Cross-Platform Optimization: The MLIR dialects facilitate cross-platform optimizations by allowing ByteIR to understand and transform code in a way that is agnostic to the underlying hardware. This universality means that optimizations are not just limited to a specific type of device or architecture, but can be applied broadly, enhancing ByteIR’s compatibility with a diverse range of computing environments.
Interoperability with Other Frameworks: By utilizing MLIR, ByteIR can interoperate with other frameworks and tools that also support MLIR. This interoperability is key for compatibility in a heterogeneous computing environment where different tools and frameworks are often used in conjunction. The ability to integrate smoothly with other systems ensures that ByteIR can be a versatile component in a broader machine learning ecosystem.
Customization and Extension: MLIR dialects allow for customization and extension according to specific needs. Developers can create custom dialects that cater to unique aspects of their models or target specific hardware optimizations. This flexibility ensures that ByteIR remains compatible with a wide array of specialized requirements, further broadening its applicability.
ByteIR Success Stories: Testimonials from the Open Source World
ByteIR is already making a substantial impact in the field of model compilation. Its success stories, highlighted through specific examples and case studies, demonstrate the significant changes and advancements it has contributed to the field.
LLM compilation with ByteIR
Here we give a case study of how we compile LLMs (Large Language Models) with ByteIR. The efficiency of training LLMs has become more and more important. Model compilation plays an important role in AI acceleration. However, it’s not trivial to adopt model compilation to LLMs, considering the graph size and complexity. With ByteIR, here is our high-level compilation workflow:
- Step 1: Capture PyTorch FX graphs through torch dynamo (aka torch.compile)
- Step 2: Preprocess FX graphs, and convert FX graphs into
mhlothrough ByteIR TorchFrontend pipelines. - Step 3: The ByteIR compiler optimizes graphs and chooses different codegen paths (LLVM GPU codegen, custom runtime kernels, AITemplate codegen, etc.) for subgraphs.
- Step 4: The ByteIR runtime processes the compiler’s outputs, launches kernel executions, and then delivers the results back to the PyTorch dynamo.
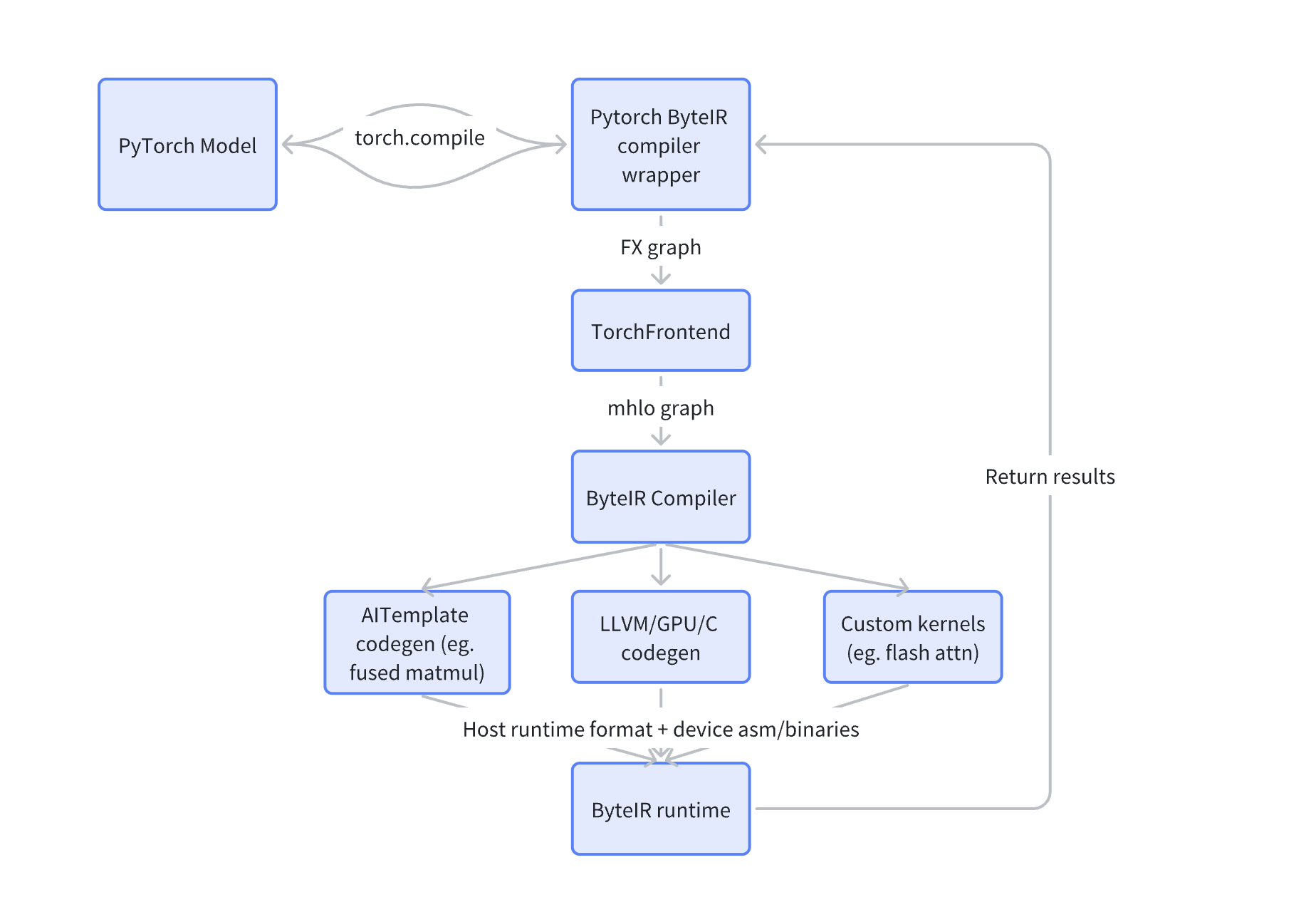
There are several codegen paths. For GPU Codegen, LLVM PTX codegen lowers GPU dialect into LLVM/NVVM dialect, and then translates it to PTX using LLVM PTX backend. Then the CUDA emitter directly translates GPU dialect to CUDA C source code. AITemplate is a Python framework which renders neural networks into high performance CUDA code(based on CUTLASS). CUTLASS is NVIDIA’s collection of CUDA C++ template abstractions for implementing high-performance matrix-matrix multiplication (GEMM) and related computations within CUDA. For AITemplate Integration, we adopt mhlo-to-CAT passes where we would convert mhlo ops to CAT ops (one CAT op corresponds to one AIT op). Flash attention is a fast and memory efficient exact implementation of attention. For flash-attention-2 integration, we match attention FX patterns, rewrite them to torch.ops.aten.scaled_dot_product_attention, and then rewrite it to byteir.flash_attn_fwd/bwd custom ops.
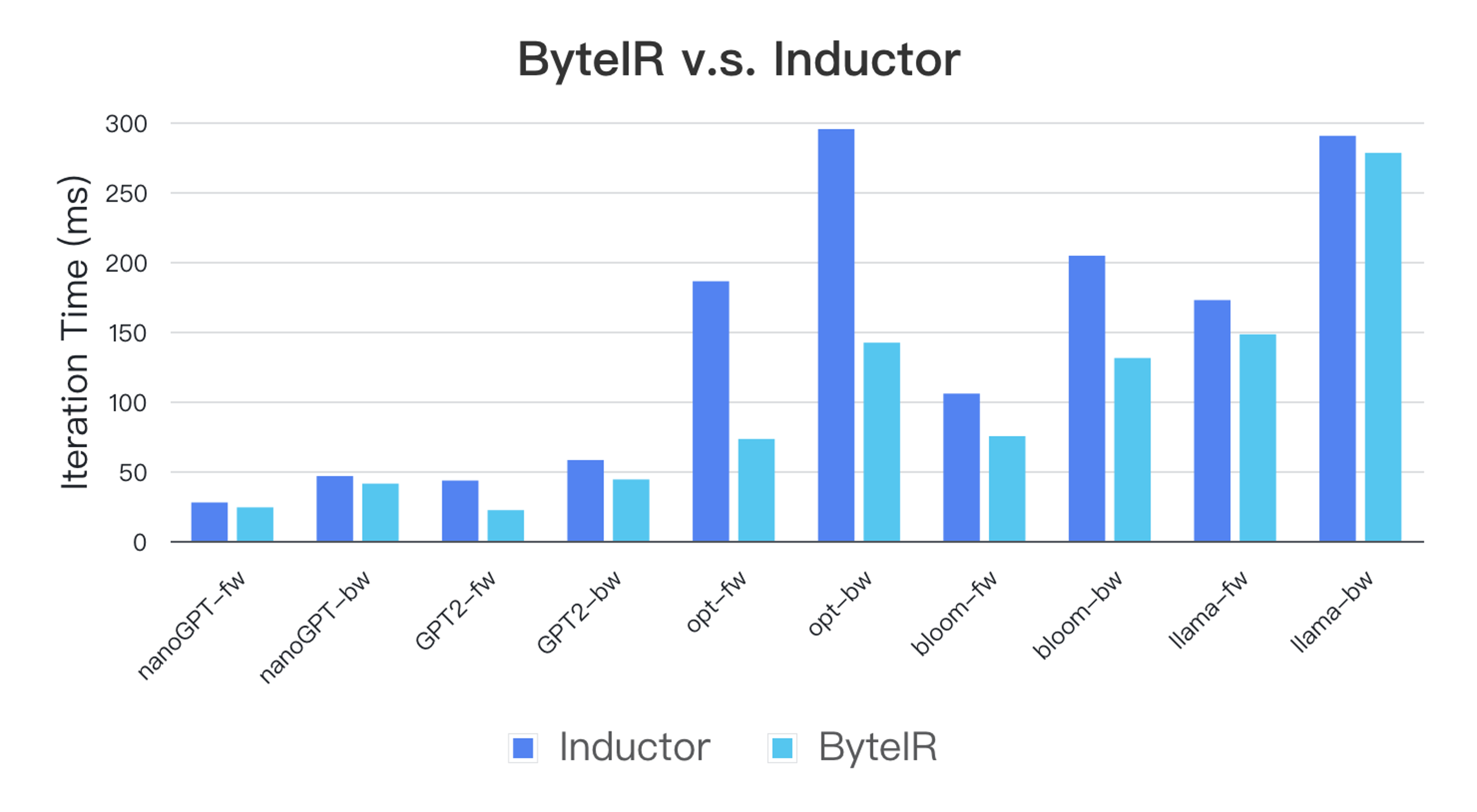
Test results show that the performance of models compiled with ByteIR outperforms that of Inductor over a wide range of LLMs. This empirically showcases performance optimization by ByteIR compiler and runtime. For end users, the benefits are as follows:
Integration of Different Frameworks: ByteIR’s ability to incorporate different frameworks is a substantial advantage. This integration allows developers to utilize the strengths of various frameworks within a single environment. It simplifies the development process, especially in complex projects that may require features from multiple frameworks. Currently, we incorporate models from PyTorch, TensorFlow, and ONNX. It can be expanded to any framework as long as we implement a frontend to lower the framework into Mhlo dialect.
Customizable Optimizations with Pass Mechanism: The pass mechanism in ByteIR enables customizable optimizations. This means developers can tailor the optimization process to the specific needs of their project. It allows for more efficient code execution and can significantly improve performance, especially in resource-intensive applications. There are already a variety of passes for different tasks and models.
Support for Different Devices: ByteIR’s compatibility with different devices broadens its applicability. This feature is particularly valuable in the current tech landscape where software needs to run across a variety of hardware platforms, from desktops and servers to mobile devices and embedded systems. This flexibility ensures that applications developed with ByteIR can reach a wider audience and are more adaptable to future technological changes. One typical example is ByteMLPerf, which relies on ByteIR to provide an AI Accelerator Benchmark that evaluates a wide array of AI Accelerators.
In summary, ByteIR’s success stories in the open-source world highlight its significant contributions and effectiveness in various domains. Through specific examples and case studies, we see how ByteIR is changing the way machine learning models are compiled and deployed. The collaborative efforts within the open-source community have been instrumental in driving these advancements, showcasing the collective power of shared knowledge and expertise in pushing the boundaries of technology.
Keeping Up to Date with ByteIR’s Fast Progress
The landscape of ByteIR is continuously evolving, with recent updates bringing significant improvements and enhancements. These updates not only refine the user experience but also expand the framework’s capabilities, particularly in terms of integration with Pytorch, enhanced GPU support, and the latest changes in its GitHub repository.
Recent PyTorch Updates
The integration of ByteIR with Pytorch has seen notable updates recently. These improvements are focused on enhancing the compatibility and performance of ByteIR when working with Pytorch models. We work closely with upstream Torch-Mlir, which aims to provide first class compiler support from the PyTorch ecosystem to the MLIR ecosystem. This in turn helps with our PyTorch integration. For users, this translates to more efficient model compilation, reduced latency in model training, and an overall smoother experience in model deployment. The updates have streamlined the process of translating Pytorch models into ByteIR’s intermediate representation, making it easier for developers to leverage ByteIR’s optimization capabilities with Pytorch’s extensive model library. PyTorch 2.0 offers the same eager-mode development and user experience, while fundamentally changing and supercharging how PyTorch operates at compiler level under the hood. It is able to provide faster performance and support for Dynamic Shapes and Distributed. We have already adapted to PyTorch 2, especially for LLMs, with a series of enhancements including flash attention support.
Enhancements in GPU Support
Another area where ByteIR has made significant strides is in GPU support. The latest enhancements are geared towards maximizing the performance of machine learning models on GPU hardware. This is particularly beneficial for applications that require heavy computational power, such as deep learning and complex data processing tasks. The improved GPU support means faster model training times, more efficient resource utilization, and the ability to handle larger, more complex models. These advancements have real-world implications, particularly in fields such as Large Language Models, search, recommendation, and audit where speed and accuracy are crucial.
Newest Features and Development Direction
The ByteIR GitHub repository is a hub for the latest developments and updates in the framework. Recent updates have brought significant changes, including major improvements in Runtime performance, ByRE versioning, and added features. The Runtime updates are particularly noteworthy, as they enhance the efficiency and stability of model execution. ByRE versioning improvements ensure better compatibility and integration with various tools and frameworks, making ByteIR more versatile and user-friendly. These updates reflect the ongoing commitment of the ByteIR team to provide a robust, high-performance tool for the machine learning community.
The latest features such as linalg extension, flash attention support for LLM models, mesh dialect, and so on, added to the repository also demonstrate ByteIR’s evolving nature. New functionalities are continuously being integrated, responding to the needs of developers and the dynamic landscape of machine learning technologies. These features not only enhance the current capabilities of ByteIR but also open up new possibilities for its application in various domains. With each update, ByteIR becomes more efficient, versatile, and user-friendly, making it an invaluable tool for anyone involved in machine learning model compilation and deployment. The recent updates are testaments to ByteIR’s commitment to continuous improvement and innovation.
Join the Movement with ByteIR
Joining the ByteIR community presents a wealth of opportunities and potential for both seasoned developers and newcomers to the field. The ByteIR platform, a dynamic and evolving tool in model compilation, is at the forefront of the open-source revolution, offering a unique landscape for learning, collaboration, and innovation.
Opportunities and Potential within the ByteIR Community:
For developers and coders, ByteIR opens up a realm of possibilities. It’s not just a tool for optimizing machine learning models, but a gateway to exploring the latest advancements in this rapidly evolving field. By engaging with ByteIR, developers have the chance to work on cutting-edge technology, contributing to and learning from projects that are at the forefront of machine learning and artificial intelligence.
One of the most compelling aspects of ByteIR is the diversity of challenges it presents. From optimizing model performance to ensuring compatibility with various hardware platforms, the issues faced within the ByteIR community are as varied as they are complex. This diversity fosters a rich learning environment, where developers can enhance their skills, gain new insights, and stay abreast of the latest trends in machine learning and computational efficiency.
An Invitation to Contribute and Learn
ByteIR is not just for experienced developers; it equally welcomes newcomers to the field. This inclusive approach is a cornerstone of the ByteIR community, emphasizing that everyone, regardless of their experience level, has something valuable to contribute. For newcomers, ByteIR offers an excellent opportunity to delve into the world of machine learning and open-source development, learning from more experienced members and gradually contributing their own ideas and skills. Contributing to ByteIR is not only about coding and technical inputs; it’s also about being part of a community that is shaping the future of technology. It’s an opportunity to collaborate with like-minded individuals, share knowledge, and build a network within the open-source and machine learning realms.
The Future Looks Bright with ByteIR
As we look towards the future, ByteIR’s role in shaping the landscape of end-to-end model compilation solutions cannot be overstated. It combines state-of-the-art technologies with a collaborative, open-source ethos that invites a wide array of contributions from its user community. This synergy between advanced technology and community-driven innovation positions ByteIR as a pivotal player in the ongoing evolution of model compilation.
ByteIR: A Keystone in Model Compilation
ByteIR stands out in the world of model compilation. Its ability to provide a comprehensive end-to-end solution is transformative for the field. By integrating various stages of model compilation into a unified, seamless process, ByteIR not only enhances efficiency but also elevates the quality of machine learning models. This efficiency does not come at the cost of versatility; instead, ByteIR ensures robust compatibility across a diverse range of devices, making it a versatile tool for a multitude of applications.
The framework’s approach to handling both model performance and device compatibility speaks to its forward-thinking design. ByteIR is adept at navigating the complexities of optimizing model performance while simultaneously ensuring that these models are deployable across various hardware platforms. This dual focus is critical in a technological landscape that values both power and adaptability.
The future of ByteIR, and by extension the field of model compilation, is inherently linked to the contributions and engagement of its user community. The opportunities that await users of ByteIR are boundless. From improving model performance to enhancing cross-device compatibility, the input from the community is vital in steering the direction of ByteIR’s development.
Every contribution, whether it’s code, ideas, or feedback, plays a part in refining ByteIR’s capabilities and expanding its reach. As you engage with ByteIR, you are part of a larger narrative of innovation and progress in the field of machine learning.